Open Source Intelligence for the Disclosure Community — A Technical Manifesto
The classification system is an infrastructure. To counter it, you need a counter-infrastructure. QDD is that counter-infrastructure, and it is built entirely in the open.
This is the technical manifesto.
The Stack
QDD is not a WordPress blog with a database bolted on. It's a purpose-built intelligence analysis platform. Here's what runs it:
Frontend: Next.js 15 + App Router. Server-rendered, edge-deployable, fast. The dark-ops interface isn't just aesthetic — it's optimized for dense data consumption. Tailwind CSS. TypeScript throughout. Deployed on Vercel.
Backend: FastAPI (Python). 14 API endpoints covering entity scoring, prediction tracking, knowledge graph queries, and more. Containerized on Google Cloud Run. Stateless. Scalable. Auditable.
Knowledge Graph: Neo4j. 414 entities and 600+ relationships stored as a property graph. Cypher query language. Sub-millisecond traversals. The backbone of every connection QDD surfaces.
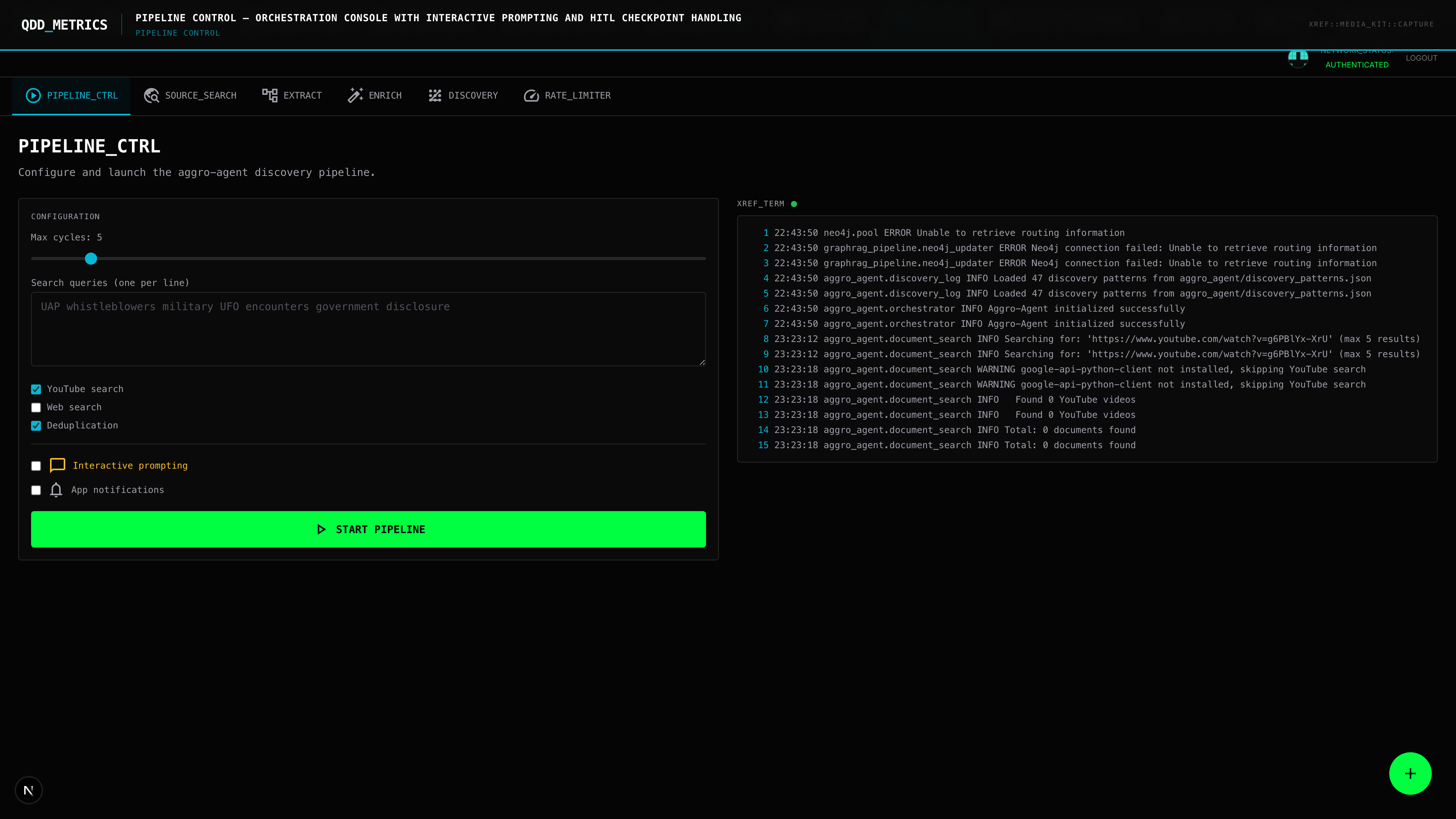
AI Layer: GraphRAG Pipeline. Natural language questions are decomposed into Cypher queries via a retrieval-augmented generation pipeline. This is not a chatbot. It's a structured query translator with source attribution on every response.
Auth & Data: Supabase. PostgreSQL-backed authentication, row-level security, real-time subscriptions. The prediction registry, community voting, and user accounts all run through Supabase.
Why Open Source Is Non-Negotiable
The UAP disclosure problem is, at its core, an information asymmetry problem. Classified programs control the data. Cleared personnel control the access. Congressional oversight is structurally limited by the very classification system it's supposed to oversee.
Building disclosure tools as closed-source proprietary platforms would reproduce the same asymmetry. A scoring system nobody can audit is just another black box. A knowledge graph nobody can inspect is just another gated dataset.
QDD is MIT-licensed. The entire codebase — frontend, backend, pipeline, schema — is on GitHub. Fork it. Audit it. Challenge it. Improve it.
This is a design philosophy, not a business decision.
The GraphRAG Architecture
The most technically novel component of QDD is the GraphRAG pipeline. Here's how it works:
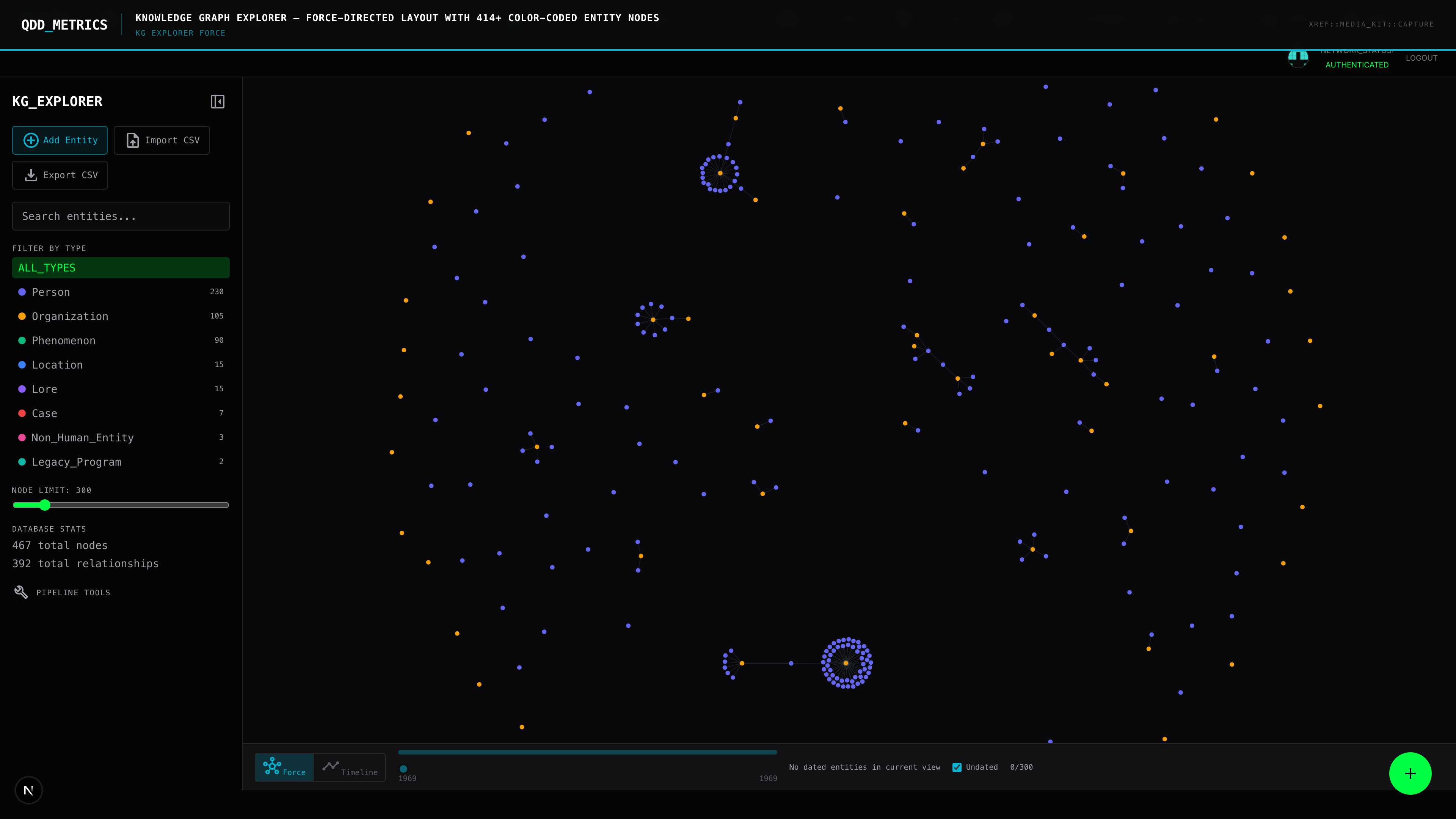
Step 1: Ingestion. Source documents — FOIA releases, congressional testimony transcripts, news articles, official reports — are processed through an NLP pipeline that extracts named entities and relationships.
Step 2: Graph Construction. Extracted entities and relationships are validated against existing nodes and edges in Neo4j. New connections are proposed. Duplicates are merged. Provenance metadata is attached to every edge.
Step 3: Query Translation. When a user asks a natural-language question, the GraphRAG pipeline identifies relevant entity types and relationship patterns, constructs a Cypher query, executes it against Neo4j, and returns results with full source attribution.
Step 4: Synthesis. Results are synthesized into human-readable answers that cite specific graph paths. No hallucination. No fabrication. Every claim traces back to a documented connection.
How to Contribute
QDD is actively seeking contributors across several domains:
Data Pipeline. New source ingestion — FOIA document parsers, congressional record scrapers, DOD organizational chart extractors.
Graph Expansion. New entity and relationship proposals. If you have domain expertise in specific UAP cases, historical programs, or institutional structures, your knowledge can be encoded as graph data.
Frontend. New visualizations, accessibility improvements, mobile optimization. The platform is built on React and Tailwind — standard tools for standard contributors.
Analysis. Methodology review. Scoring system critiques. Prediction resolution debates. The adversarial audit is as valuable as the code.
The repository is live. Issues are tracked. PRs are reviewed.
The Endgame
Classification is an infrastructure of secrecy. QDD is an infrastructure of transparency. Both are technical systems. Both are maintained by people. The difference is that one of them is open.
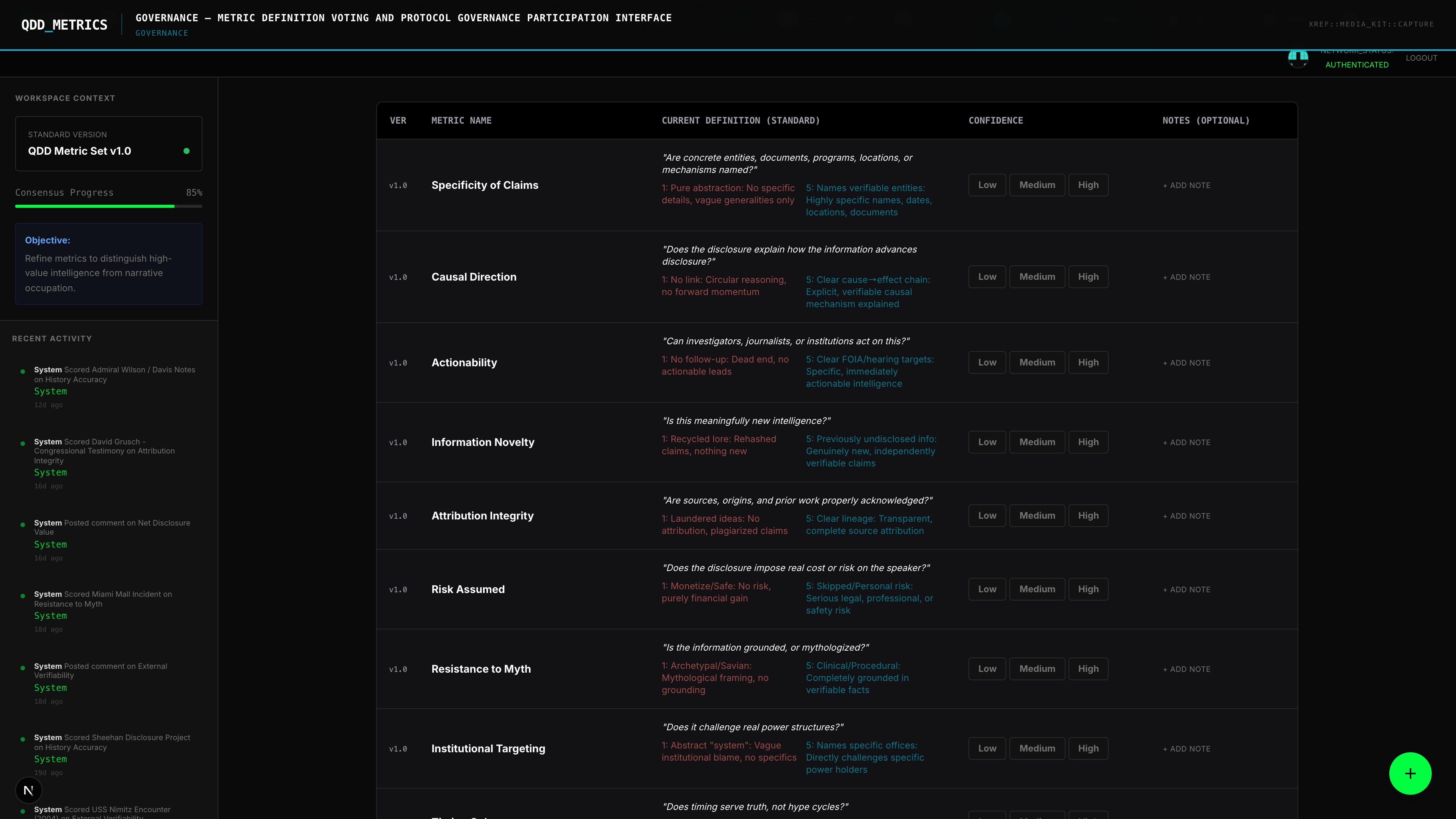
Every entity. Every connection. Every score. Every prediction. Auditable. Forkable. Owned by no one.
This is what disclosure infrastructure looks like when the community builds it.