Tracking UAP Predictions: How QDD's Prediction Registry Works
Developing:
Everyone in the UAP space makes predictions. Whistleblowers forecast congressional action. Researchers predict document releases. Commentators call timelines on disclosure milestones.
Almost none of them are tracked. The prediction is made, the timeline passes, and the discourse moves on. No accountability. No record. No learning.
QDD's prediction registry changes that.
The Accountability Gap
Here's a pattern that repeats every six months in the UAP community:
A credible source makes a specific, testable prediction. The community amplifies it. The deadline arrives. The prediction either resolves or doesn't. Either way, the discourse treats the next prediction from the same source with identical credulity.
This is an intelligence failure. Not of collection — of analysis.
The IC tracks source reliability across predictions. If an asset's intel doesn't pan out, their reliability rating drops. Future reporting from that source gets weighted accordingly.
The UAP disclosure community has no equivalent mechanism. QDD builds one.
How the Registry Works
Every prediction in QDD is structured as a testable claim with defined resolution criteria.
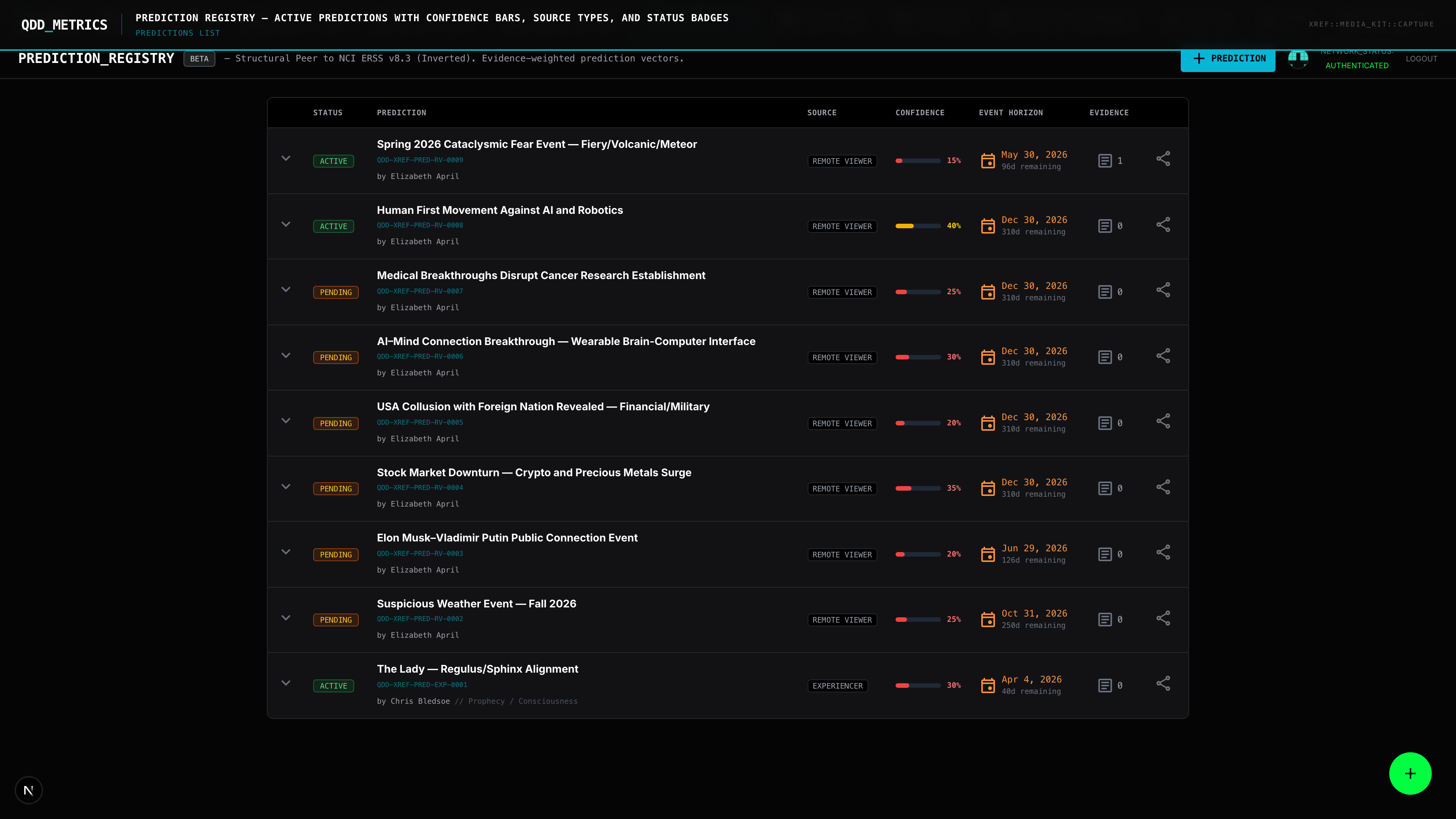
Claim Registration. A prediction is entered with its exact text, source attribution, date made, and predicted timeline. No paraphrasing. No editorializing. The original claim, as stated.
Evidence Aggregation. As events unfold, evidence for or against the prediction is attached. Congressional votes. Document releases. Official statements. Each piece of evidence is sourced and timestamped.
Resolution Scoring. When sufficient evidence exists, the prediction is scored: confirmed, partially confirmed, unresolved, or refuted. The scoring methodology is transparent — anyone can see what evidence drove the assessment.
Source Impact. Resolution outcomes feed back into the credibility scoring system. A source whose predictions consistently resolve correctly earns higher reliability scores. A source whose predictions consistently fail sees their scores adjusted.
What's Being Tracked
The registry launched with predictions spanning several active fronts in UAP disclosure:
Legislative predictions. Will the UAP Disclosure Act provisions survive the NDAA conference process? Will a standalone UAP transparency bill reach the floor? Specific claims from legislators and insiders are on the clock.
Institutional predictions. Will AARO release its full historical review? Will the ODNI comply with congressional reporting mandates? Will new whistleblowers come forward through the Inspector General pathway David Grusch established?
Evidentiary predictions. Specific claims about crash retrieval programs, reverse engineering efforts, and biological evidence — each registered with clear resolution criteria.
Community Scoring
The registry includes a community voting mechanism. Users can register their own confidence levels on active predictions, creating a crowd-sourced probability layer alongside the editorial scoring.
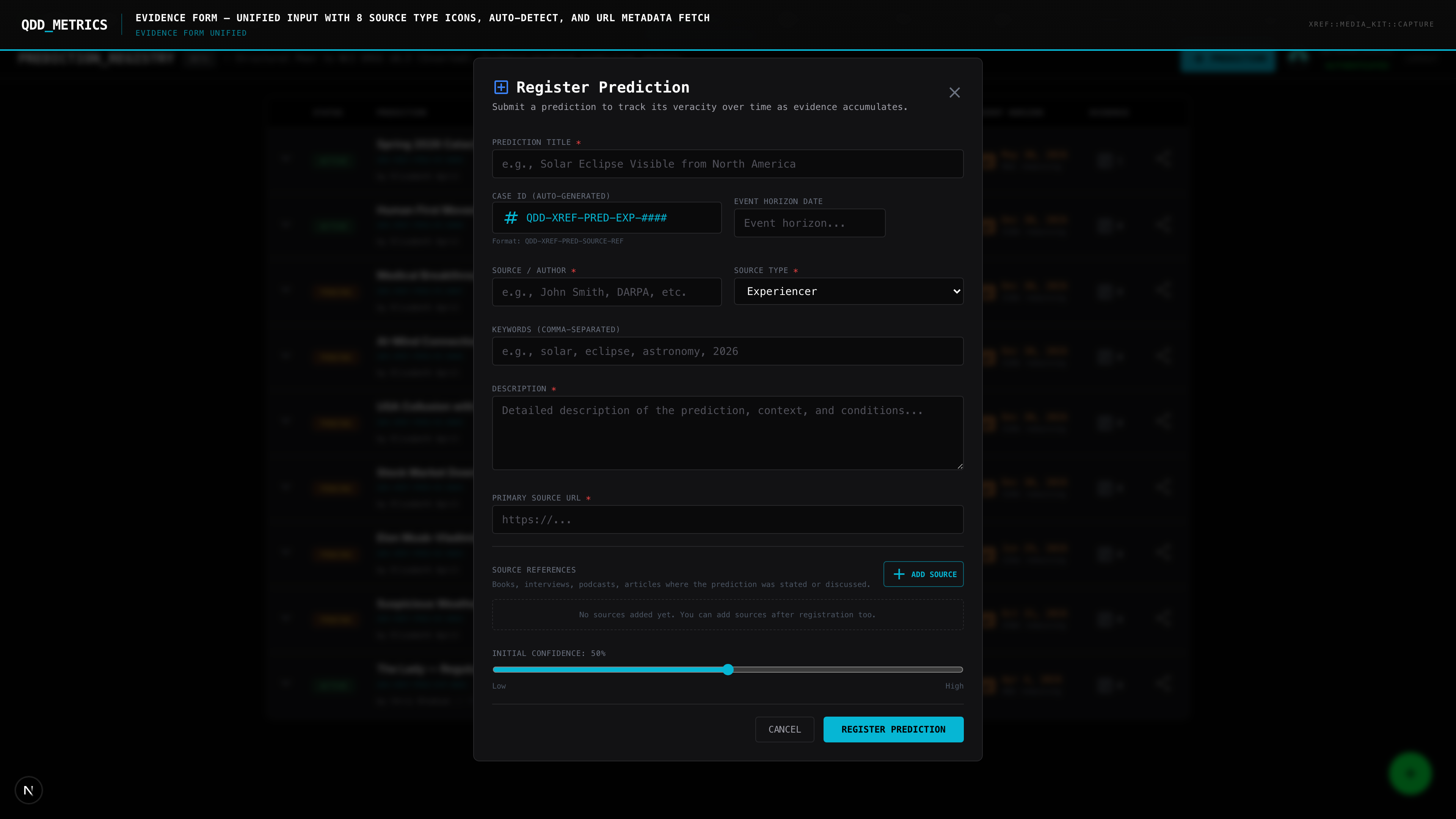
This isn't a popularity contest. It's a Bayesian signal — what does the informed community collectively assess as likely? When community consensus diverges sharply from expert assessment, that gap itself is a data point.
Why This Matters
The UAP discourse is approaching a critical mass of testable claims. Between Grusch's ICIG complaint, AARO's historical reviews, and active congressional legislation, more predictions are on record now than at any point in the field's history.
Without a tracking system, those predictions become noise. With one, they become data.
QDD's prediction registry is live and growing. Every claim. Every timeline. Every resolution.
The record doesn't forget. Neither does the registry.